机器学习 - Perceptron 和 Neural Networks
Perceptron
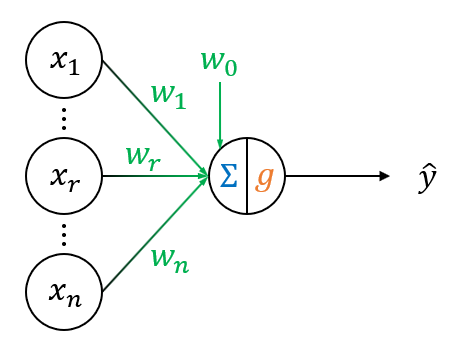
感知器,是一个线性分类器(Linear Classifier)。
其中 \(x_r\) 为输入,\(w_r\) 为权重(weights),\(w_0\) 为偏置项(bias term)。
\(g\) 为激活函数(activation function),在感知器中 \(g = \mbox{ unit step function }\)。
\(\hat{y}\) 为输出,\(\hat{y} = u(\sum_{r = 0}^n w_r x_r)\)。
使用向量表示:
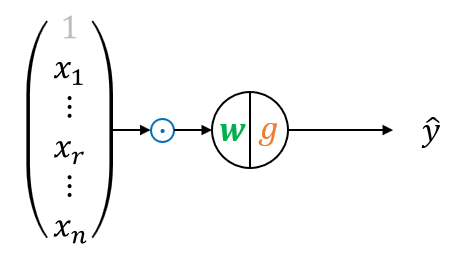
\(\hat{y} = u(w^\mathrm{T} x)\)。
PLA
Perceptron Learning Algorithm
步骤:
初始化权重 \(w\),可以是全 0,或者随机数值
对于任意一个特征为 \(x^{(i)}\) 的实例 \(i\),进行分类计算:\(\hat{y}^{(i)} = u(w^\mathrm{T} x^{(i)})\)
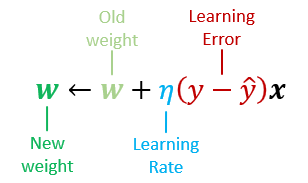
选择一个分类错误的的实例,进行权重的更新:\(w \leftarrow w + \triangle w\)
重复步骤 2 和 3 直到误差减小至阈值或者迭代次数到达最大值
权重更新:
感知器是线性分类器,也就是说它无法对非线性可分数据进行分类。
要实现非线性分类,需要
其他激活函数
多个感知器:Multi-Layer Perceptron (MLP)
Activation Functions
Unit Step
\[
u(x) = \begin{cases}+1\ x > 0 \\ 0\ x \leq 0\end{cases}
\]
Sign
\[
\mathrm{sgn}(x) = \begin{cases}+1\ x > 0 \\ -1\ x \leq 0\end{cases}
\]
Sigmoid
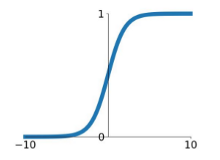
\[
\sigma (x) = \frac{1}{1 + e^{-x}}
\]
tanh
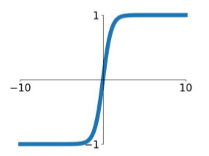
\[
\tanh (x)
\]
ReLU
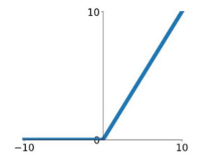
\[
\max (0, x)
\]
如果 \(g\) 是可导的,那么可以用梯度下降法来快速找到 \(\varepsilon = y - \hat{y}\) 的最小值。
Sigmoid,tanh 和 ReLU 是非线性激活函数,且是可导的。
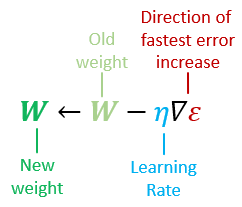
Gradient Descent
梯度下降法
权重更新(single neuron):
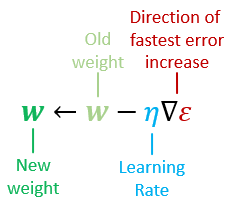
\[
\triangledown \varepsilon = \frac{\mathrm{d}\varepsilon}{\mathrm{d}w} = \begin{pmatrix}{\partial\varepsilon / \partial w_1}\\ \vdots \\{\partial\varepsilon / \partial w_r}\\ \vdots \\{\partial\varepsilon / \partial w_n}\\\end{pmatrix} = \frac{\mathrm{d}\varepsilon}{\mathrm{d}g} \frac{\mathrm{d}g}{\mathrm{d}f} x
\]
Binary Cross-Entropy (for classification)
\[
\varepsilon = -y \log \hat{y}
\]
Square Error (for regression)
\[
\varepsilon = \frac{1}{2}(y - \hat{y})^2
\]
| Error \(\varepsilon\) | \(\mathrm{d}\varepsilon / \mathrm{d}\hat{y}\) | Activation Function \(\hat{y} = g(f)\) | \(\mathrm{d}g / \mathrm{d}f\) |
|---|---|---|---|
| Square Error | \(-(y - \hat{y})\) | Sigmoid | \((1 - g)g\) |
| Binary Cross Entropy | \(-\frac{y}{\hat{y}}\) | tanh | \(1 - g^2\) |
| ReLU | \([f > 0]\) |
Neural Networks
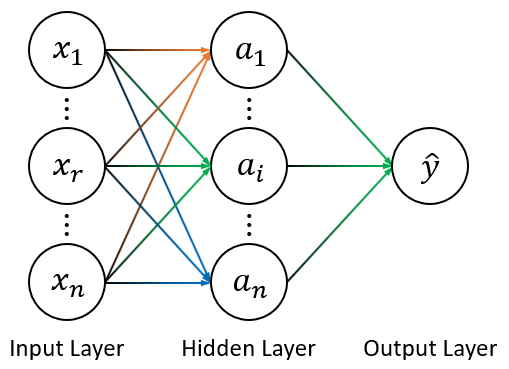
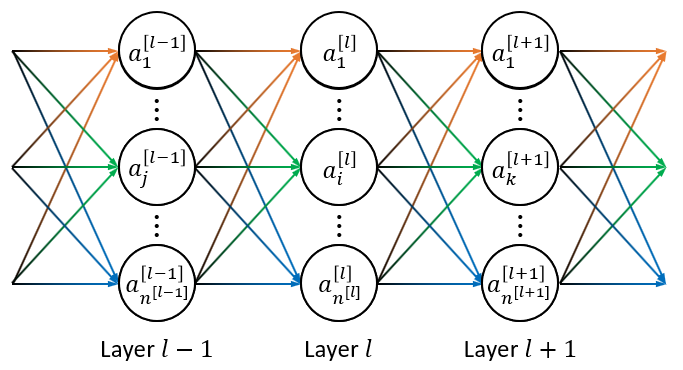
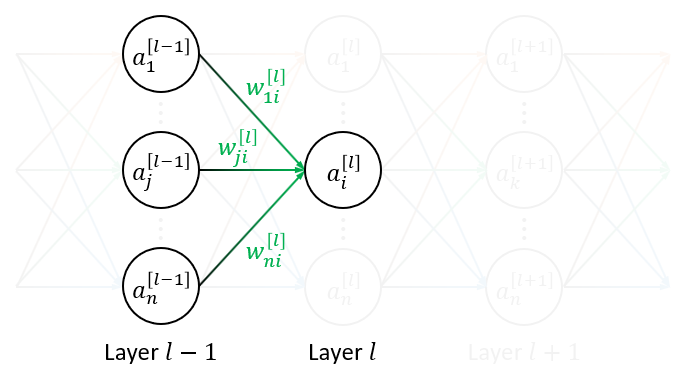
使用向量表示:
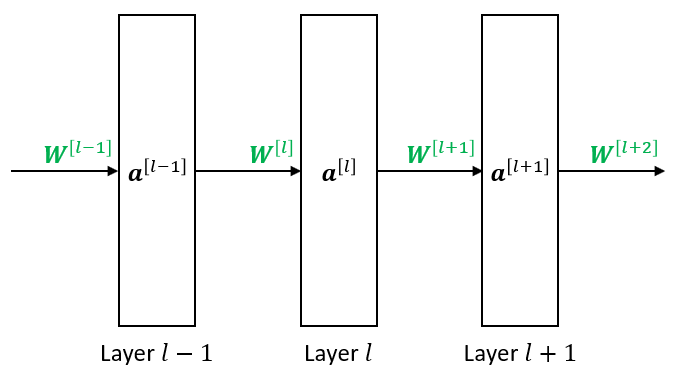
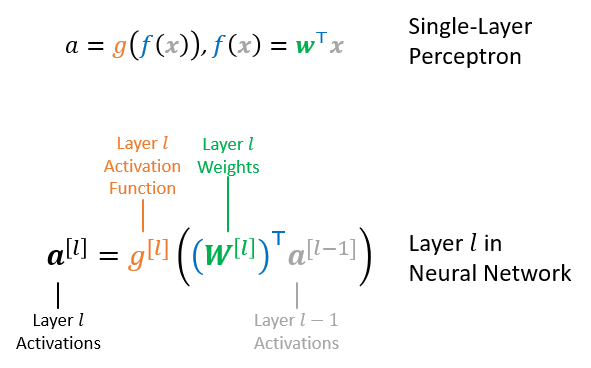
Layer Activation:
Backpropagation
权重更新(neural network):
\[
\triangledown \varepsilon = \frac{\mathrm{d}\varepsilon}{\mathrm{d}W} = \begin{pmatrix}{\partial\varepsilon / \partial W^{[1]}}\\ \vdots \\{\partial\varepsilon / \partial W^{[l]}}\\ \vdots \\{\partial\varepsilon / \partial W^{[L]}}\\\end{pmatrix}
\]
\[
\frac{\mathrm{d}\varepsilon}{\mathrm{d}W^{[l]}} = \frac{\mathrm{d}\varepsilon}{\mathrm{d}\hat{y}} \frac{\mathrm{d}\hat{y}}{\mathrm{d}W^{[l]}}
\]
计算 \(\mathrm{d}\hat{y} / \mathrm{d}W^{[l]}\):
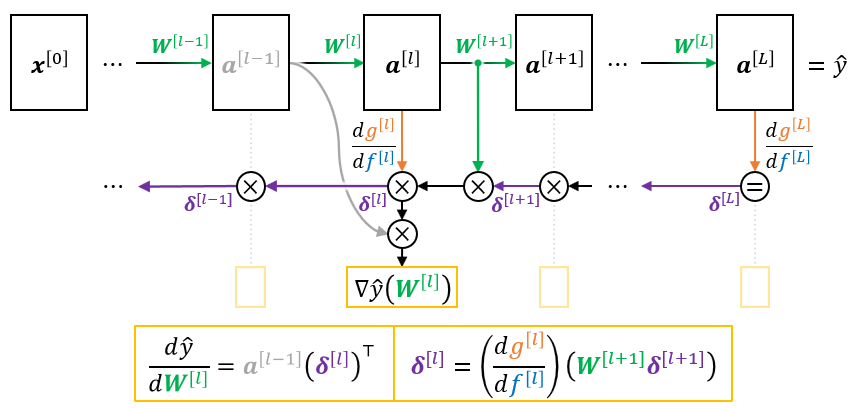
We calculate the gradient \(\mathrm{d}\hat{y} / \mathrm{d}W^{[l]}\) of the current layer \(l\) as the multiplication of:
Previous layer’s activation \(a^{[l -1]}\)
Current layer’s gradient of the activation function \(\mathrm{d}g^{[l]} / \mathrm{d}f^{[l]}\)
Next layer’s weights \(W^{[l + 1]}\)
Backpropagated partial gradient from later layers \(\delta^{[l + 1]}\)
 wechat
wechat alipay
alipay
